AtCoder 茶色になったので振り返りと茶色になるために必要だと思うことを書く
最初に一言。茶色になるのは想像以上に大変だった。
tl;dr
- C++ の学習と AtCoder のコンテスト参加を今年の 4 月頃から始めて、12 月に茶色になった
- 茶色になるまでの振り返りと、現在(2020年)の AtCoder で茶色になるために必要だったことを書いていく
AtCoder をはじめる前の実力とかモチベーション
- 5月頃に書いていたのでそちらを参照
- 精進自体は断続的にやってたと思うが、1日1時間ぐらいちゃんとやるようになったのは 9 月以降ぐらいかもしれない
レート遷移
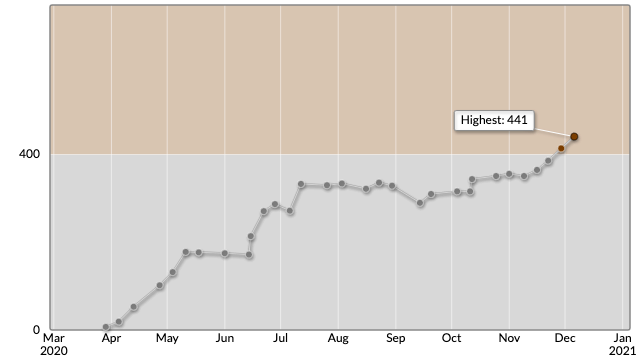
開始 1ヶ月
- A, B 問題は AC できることが多かった(WA することもあった)
- レート補正もあったので参加すればするだけ順調にレートは伸びた
- 意外と AC できて楽しい
開始 2ヶ月
- レート 170 で停滞
- 始めは相性の良いコンテストが続いていただけで、実際の実力はこれぐらいであることが判明。辛い。

- 多分これぐらいの時期に AtCoder の実行時間制限と計算量の見積もりを理解し始めた(それまでは勘)
- あと WA するとペナルティ受けるらしいことを知った気がする
開始 3 ~ 4ヶ月
- レート 300 まで成長
- 一応精進はしていたが単純にコンテストの相性が良い回があってレートが上がった感じ
- しかしここからが長い
- 多分ようやく C++ の標準ライブラリの使い方に慣れてきた頃(pair は便利、sort はこう書けるのか等)
- 精進は何を勘違いしたのか D 問題の練習してたと思う
開始 5 ~ 7ヶ月
- レート 300前後を彷徨う
- 精進しているにも関わらずむしろレートが下がる暗黒期
- ABC 178 でパフォ 79 叩き出して泣きそうになってた。なんで初めてコンテスト参加したときより低いんだ?
- コンテスト本番の実戦力の欠如もレートが安定しない原因だったと思う
- A 問題で少し悩む -> 焦る -> B 問題で悩む -> 焦る -> (思考リソース枯渇)-> 死
- このあたりで、自分はアルゴリズムの勉強する領域には達して無くて、 A~C 問題を大量に練習しなきゃいけないレベルなんだ、と自己認識を改めた(謙虚さが大事)
- この頃ぐらいから数学的な思考みたいなものを取り戻し始めた感覚があった(大学受験以降は全然数学してなかった)
開始 8ヶ月~ 茶色
- 過去のコンテストの演習を積んで、C 問題レベルまでを解くときに必要な知識とか注意点が分かってきた
- レートが単調増加を始める
- この時期は ABC よりも ARC が大量に開催されるようになっていて、ARC だと安定して 500~600 ぐらいのパフォーマンス出せたというのも大きい
- 昔から処理能力が評価されるテストが苦手だったというのはありそう(センターより記述式が好きだった)
- 正直今でも ABC は怖いです
やって良かったと思うこと
- 過去の ABC コンテストを時間を計りながら解く(A~C 問題レベルを大量に解く)
- 1.5 倍速で解説放送を見る
- 解けなかった問題は何が自分に不足していたのか振り返って記録を残す
- 解けなかった問題を繰り返し解く(Solve Later Again)
- とりあえずコンテストには出場し続ける
- 実装の方針が思いつかないときに検討することリストを自分なりに整理する
やらなくても良かったと思うこと
- C++ を Web のチュートリアル と AOJ で学習(AtCoder のために学習するなら普通に AtCoder の問題解いた方が効率良い)
- A ~ C 問題を安定して解答できないのに D 問題(茶 Diff )で要求されるアルゴリズムの勉強をする(そのうち役に立つことは間違いないが、多分レートが上がらない間の精進が辛くなる)
茶色になるまでに必要そうなこと
C++ を使っていて灰色で停滞している人向け。他の言語は分からん。 多分高レートの人が書くと当然すぎて省略されたり、もう記憶になかったりすると思うような細かいことも書いていく。 ちなみに、多分最速で茶色目指すなら C++ より Python の方が良いと思った。C++ よりもオーバーフローや誤差を気にしなくても良いので...
場合分け
- 考察の基本。数学でやるのと同じ。
- 愚直に場合分けして整理するだけで O(1) で済むならそれが 1 番良い
全探索
- 全探索で済む問題なら全探索一択(バグりにくい)
- 下手な考察で全探索を回避しようとしない方がいい
- bit 全探索が使えないかは心に留めておく。 n = 218 ぐらいなら全然間に合う。
n = 108 以内に収まらない場合の工夫
- 問題の性質を活用することで単純な全探索を効率化する(探索対象や範囲を変更する)
- 集合 A から全探索して集合 B を見つけるのではなく、集合 B として考えられる全事象を全探索するとか
- 集合 B のパターンが限定的で、集合 A の判定が 少ない計算量で済むなら有効(ABC181 D)
- 全探索?楽勝www みたいな感じに思いがちだが色々とパターンはあるので経験を積むのが大事
- 集合 A から全探索して集合 B を見つけるのではなく、集合 B として考えられる全事象を全探索するとか
切り上げ
- C++ は整数型同士の除算は切り捨て
a / bの切り上げをしたい場合は(a + b -1) / b
min と max
- 使える場面を意識するとコードが見通しよくなる
a = max(a, 0)で a の最小値を保証したり、b = min(b, 30)b の最大値を保証したり
分布を使う
- map 型の活用。最初の頃は意識しないと浮かんでこない発想だった。
- ABC 172 C、ABC159 D、ABC 139 C
オーバーフロー
- long long でも 約 9.2 * 1018 までしか扱えない
- オーバーフローが式の途中でも発生しないように注意する(式変形も考慮する)
`for(ll i=1; i*i<=n; i++)で i = 109 を超えるような場合とかに注意
誤差
- double 同士の計算は誤差がある
- 7.29 * 100 = 728.999 みたいになることがある
- ABC 169 B
- double の仮数部は 約16桁 ( ARC 109 B でルートを取る場合に誤差)
- 誤差許容の問題の場合の出力は、
printf("%.12f", ans)ぐらいしておくと良い(ABC 126 C)
整数
- 事前に学習してないと辛い
- lcm、gcd、約数・素数列挙
ちょっとした変換
文字コードを加算・減算することで簡単に変換できる
- 小文字 -> 大文字変換
printf("%c", t - 32); - 大文字 -> 小文字変換
printf("%c", t + 32); - 文字列 -> 数値 : '1' - '0' -> 1 に変換
- 数値 -> 文字列 : to_string(1)
整数の切り出し
- 上2桁、下2桁を切り出す
1234 / 100 -> 121234 % 100 -> 34
- 順番に切り出す
int dx = 12345;
while(dx) {
cout << dx % 10 << endl; // 5, 4, 3 ...
dx /= 10;
}
その他
A ~ C 問題でもわりと頻出の考え方
- 貪欲法
- 累積和
- 簡単な DP
今後について
- 茶色になって区切りが良いのと、本業の学習にも注力したいので続けるか悩み中
- 元々は趣味が欲しいと思って始めたことだが、本業でエンジニアやってて灰色で挫折しましたっていうのは悔しいみたいな感情にも突き動かされていたので茶色になって満足感が強い
- でもコンテスト自体が良い脳トレとコーディング力の維持にはなっている感覚があってこの状態は保ちたいんだよな
React v16 まではイベントハンドラが window.document に登録されていたという話
@koba04 さんの React v17 の変更に関するこぼれ話 を読んで、コードを動かしてみたので書く。
v16 でイベントハンドラは document に登録される
React v17 の変更に関するこぼれ話 に記載されている通り、React v16 までは React 内のイベントハンドラは document に登録される
元記事のコード例 でgetEventListeners(window.document) すると、window.document に React のクリックイベントが登録されていることが分かる。
- なので
button->bodyじゃなくて - (
buttonスキップ) ->body->documentの順にイベントが伝搬する
ちなみに、コンポーネント内のイベントの親子関係は保たれるので
<div onClick={()=>{console.log("div click")}}> <button onClick={()=>{console.log("button click")}}>
のような場合は button -> div の順に実行される。
v17 で getEventListeners(window.document) する
v17 では ReactDOM.render の第2引数にイベントハンドラが登録されるので、getEventListeners(window.document) すると空が返ってくる。
業務で直面した問題
結論としては特に↑で書いたこととは関係なかったが、こんな現象に業務で出会ったので余談として書いておく。
- React v16 を使用していて
- オーバーレイの子要素としてモーダルを設置
- オーバーレイ、モーダルのボタンにクリックイベントを設定
- モーダルのボタンをクリックするとオーバーレイに設定したイベントが優先して発火される(なんで??)
v16 までのイベントハンドラが document に登録される仕様のせいだったりするのかなーと思ったが、React コンポーネント内の onClick イベントしか使っていない。よくよく見ると、
- イベント自体はボタン -> オーバーレイの順に伝搬している
- ボタン押下時に API コール -> レスポンスに応じてモーダルを更新する処理が走る
- でも↑が非同期処理なので先にモーダル(とオーバーレイ)を閉じる処理が走り、そうするとモーダルの更新処理が反映されない
というオチだった。ちなみに、オーバーレイの子要素にすると、ダイアログのどこをクリックしても閉じてしまうので兄弟要素にするか、元記事でも紹介されていたように適切にクリック要素を判定する する実装が必要になる。
Go の module cache と vendor の違い
Go の module cache と vendor の違いがよく分からなかったので調べた。結論としては、違いというか go.mod に記述されているバージョンによってデフォルトで module cache と vendor のどちらを go run や go build 時に使うかが異なる。
環境
- Go 1.15.3
$GO111MODULE= ON
module cache
- 外部のモジュールに依存したコードをビルドする場合、依存モジュールを1度ダウンロードする。ダウンロードしたモジュールは、
$GOPATH/pkg/mod/にキャッシュされるので次回のビルド時には再度ダウンロードする必要はなくなる。 go clean --modcacheで消せるgo run -mod=modフラグで明示的に module cache を使用するように指定できる
vendor
go mod vendorすると外部の依存モジュールをvendorディレクトリにダウンロードするgo run -mod=vendorで明示的に vendor ディレクトリを使用するように指定できる- コードのビルド時のデフォルト動作として、 vendor が使われるかどうかは、go.mod ファイルのバージョン記述に依存する。
// go.mod module github.com/pokuwagata/ichigo-cli go 1.15 <- これ require github.com/urfave/cli/v2 v2.1.1
- Go 1.14 以降は vendor が優先して使用される。1.14 未満の場合は module cache が優先される。
なぜ module cache と vendor の両方が存在するのか
- module mode は Go 1.11 から使えるようになったが、それ以前は module cache を使っていて、現在は移行・後方互換性のために残留しているっぽい。詳しくは分からない。
参考
パスカルの三角形を利用して組み合わせの数を求める
ABC 132 D 問題 の公式解説で、パスカルの三角形を利用して組み合わせの数を求めていたが、一見して何をしているか理解できなかった。
実装はこんな感じで、nCk を計算できる。
int n, k; cin >> n >> k; int c[105][105] = {}; c[0][0] = 1; for(int i=0; i<=100; i++) { for(int j=0; j<=i; j++) { c[i+1][j] += c[i][j]; c[i+1][j+1] += c[i][j]; } } cout << c[n][k] << endl;
パスカルの三角形とは何か、パスカルの三角形がなぜ組み合わせの数と対応するのかはこちらを参照して頂くとして、自分が分からなかったのはこの実装でパスカルの三角形が求められる理由。
これは図で書いてみると分かりやすくて、c[i][j] を下段の c[i+1][j], c[i+1][j+1] に配っているイメージ。
○ | \ ○ ○ | \ | \ ○ ○ ○
これなら両端は必ず1になるし、両端以外はパスカルの三角形の定義通りの加算が行われた値になる。
ちなみに、組み合わせの数は公式を使って愚直に計算しても(数が大きくなければ)良いと思う。
int n, k; cin >> n >> k; int ans = 1; for(int i=0; i<k; i++) { ans *= n-i; } ans /= k; cout << ans << endl;
ただし、組み合わせの数を求める度に O(k) の計算が必要になるのと、掛け算がオーバーフローする可能性もあるので、パスカルの三角形で事前に計算しておいた方が良い場合も多そう。
総和の剰余(mod) を計算したい
C - Sum of product of pairs で躓いたのでメモ。
総和の剰余(mod)
整数 a1, a2, a3 ... の 総和の剰余(mod) を計算したい。
(a1 + a2 + a3 ... ) % m
このとき、上の計算は以下と同値である。
(a1 % m + a2 % m + a3 % m ... ) % m
これを剰余演算の分配法則と同一性から示す。
剰余演算の分配法則から以下が成り立つ。
(a1 + a2) % m = (a1 % m + a2 % m) % m
すると、以下のように変形できる。
(a1 + a2 + a3 ... ) % m = (a1 % m + (a2 + a3 ... ) % m ) % m = (a1 % m + (a2 % m + (a3 + a4...) % m) % m) % m ... = (a1 % m + a2 %m + ...) % m % m ...
また、剰余演算の同一性から以下が成り立つ。
a % m = (a % m) % m
したがって、
(a1 % m + a2 %m + ...) % m % m ... = (a1 % m + a2 %m + ...) % m
と変形できる。
なので、総和の剰余を求める場合は、剰余の総和を取って最後に剰余を取ってもいいし
int sum = 0; for(int i = 0; i < n; i++) { sum += a[i] % m; } sum %= m;
変形前の式から見ると、加算する度に剰余を取ってもいい(オーバーフローを防げるので安全)
int sum = 0; for(int i = 0; i < n; i++) { sum += a[i] % m; sum %= m; }
(+-*)の演算をする度に剰余を取ると思っておいて良さそう。除算は逆元が絡むのでまた別の話。
参考
TypeScript の演算子を整理する
TypeScript (というか最近のJavaScript)って、よく分からない演算子多くないですか? なんか色々な箇所で! とか ? とか見るので意味が分からないと結構ストレスになります。
自分があんまりキャッチアップしてないのが悪いんですが、馴染みがない/薄い演算子について使い方と登場の背景を整理した自分用のメモ。
- Nullish Coalescing (??)
- Optional Chaining(?)
- Optional parameter (?)
- rest parameters (...)
- Non-null assertion operator (!)
- Short-Circuiting Assignment Operators (&&=, ||=, ??=)
Nullish Coalescing (??)
こういうやつ
let x = foo ?? bar();
要はこれのシンタックスシュガー
let x = foo !== null && foo !== undefined ? foo : bar();
なぜ必要か
JavaScript を書いてフロントエンドの開発をすると上のような書き方を頻繁にするから。特にレガシーなフロントエンドのコードベースに少し手を入れる時なんかは、どの変数がいつ null や undefined になるか予想がつかない場合も多く、とにかく安全側に倒したかったりする。(例外が発生すると処理が止まるので)
ちなみに、単に x = foo || bar() と書くと、foo が 0 だったり空文字だったりすると false になって bar() が評価されるので困る。JavaScript 初心者が絶対に1度はハマる罠。?? だと NaN は回避されないみたいですが。
Optional Chaining(?)
こういつやつ
let x = foo?.bar;
要はこれのシンタックスシュガー
let x = foo === null || foo === undefined ? undefined : foo.bar;
なぜ必要か
let x = foo && foo.bar とか書きたくないから。これもレガシー系フロントエンドの改修でありがちで、オブジェクトのプロパティと値がまったく予想できないので、こう書くしか無いパターンが多かった。とても助かる。がそもそも使わなくても良いのが望ましいとは思う。
Optional parameter (?)
こういうやつ
function foo(bar?: string) { ... }
? を付けると string | undefined 型に推論される。これは厳密に演算子という区分なのかは分からないけど、まあそんな感じのものだと思ってる。
なぜ必要か
JavaScript の関数の引数は全て省略可能だが、引数が与えられない可能性があるのか、ないのかは区別できた方が嬉しい。そしてそうしないと型定義できない。
rest parameters (...)
こういうやつ
function foo (bar: string, ...baz: string[]) { ... }
引数を無限に受け取ることを宣言できる。spread operators とはまた別だと思う。
なぜ必要か
無限に引数を受け取ること自体は従来からできて、 関数内から arguments で参照可能だった。ただし引数の宣言からはそれが読み取れなかったので分かりやすくなった。そしてそうしないと型定義できない。
Non-null assertion operator (!)
こういうやつ
function foo(f?: Foo) { let bar = f!.bar; }
要はこれのシンタックスシュガー
let bar = (f as Foo).bar;
なぜ必要か
外部のライブラリの型定義上 foo | undefined みたいに定義されているが、自分の実装上は絶対に undefined にならないから何とかしたいみたいなときに使うことが多い気がする。(自分が定義した型でこれが頻出するならそもそも型定義を見直した方がいいんじゃないか)
Short-Circuiting Assignment Operators (&&=, ||=, ??=)
こういうやつ
a &&= b; a ||= b; a ??= b;
要はこれのシンタックスシュガー
a = a && b; a = a || b; a = a ?? b;
ちなみに、JavaScript に馴染みがなかったり、しばらく別の言語を書いていたりすると、「え? a && b とか a || b って bool 型しか返さないのでは?」となるかもしれない。
JavaScript の場合はそんなことはなく、短絡評価をして
a && b:a が false なら a を返すa || b:a が true なら a を返す
という仕様になっている。この true か false かというのは、bool 型を期待しているわけではなく、JavaScript 流の解釈で、0, "", NaN, undefined, null ... 等は false でそれ以外が true みたいな感じに評価されるだけ。
非 bool 型の a, b で if(a && b) のように書くと、(if 文の条件式なので)返値が bool 型に変換されるのでそれっぽく振る舞っているだけという感じ。
なぜ必要か
正直、自分はあんまりこういうコードが必要になったことはない。まず、変数に対する再代入をすることがあまりない。JavaScript が一部継承している関数型プログラミングのパラダイム的にも推奨してないと思う。
一方、競プロの問題を解く時は手続き的にサッと書きたいので、sum+=a とか sum /= a とかは頻繁に使う。でも a &&= b はあっても使うことないと思う。
あと、a ||= b するなら大抵は a ??= b の方が適切じゃないかと思う。上でも書いたけど、0 とか 空文字を false として扱って欲しいケースの方が少ない気がするので...
(a + b - 1) / b で a / b の切り上げを計算する
整数 a, b に対して、 a / b の切り上げを計算したい場合 (a + b - 1) / b するという小技が競技プログラミングではよく使われる。
なぜこれで切り上げが計算できるのか、良い感じの説明が検索しても出てこなかったので自分なりの理解を書いておく。
以下 / は一時的に分数の記号として、 b = 3 , a を 3から1ずつ増加させていく場合を考える。
3/3 = 1 4/3 = 1+1/3 5/3 = 1+2/3 6/3 = 2 7/3 = 2 + 1/3 ...以下略
となるので、1 - 1 / b (b=3 の場合は 2/3) を加算して小数点以下を切り捨てれば切り上げと同じになる。
切り上げすべき場合は必ず商が繰り上がる。
切り上げすべきでない場合(上記の 3/3 , 6/3 のケース)は商が繰り上がらない。
よって、floor(a/b + (1-1/b))をすればよく、今度は / を切り捨て除算の記号として式変形すると
(a+b-1)/b で同値と言える。したがってa / b の切り上げを計算したい場合 (a + b - 1) / b で計算できる。
ceil が使える言語ならそれでもいいんじゃないか?と思われるが、a, b の値によっては浮動小数点計算の誤差が発生する可能性があるので、この方法が安全らしい。なるほど。
まあ (a+b-1)/b の方がシンプルだし賢いやり方感がある。