ブログの更新を停止します
今後は以下のブログに記事を書いていきます。というか既に書いています。
はてなブログの記事は残しておきます。既存の記事を更新する場合は新しいブログに記事を書きます。よろしくお願いします。
React Server Components で SSR する場合の Hydration について調べてみた
React Server Components (RSC) について学んでいる中で、Server Component (SC) を SSR した場合に Hydration はどうなるんだろう?と疑問に思ったので調べてみたメモ。間違っていたらすいません。
これまでの Hydration
クライアント側の JS に hydrate すべきコンポーネントが存在するので、普通にhydrateRoot(dom, <App />)
SC の Hydration
SC の JS はクライアントに配信されない。これによってクライアント側のコード量が減るのが RSC の利点の1つ。
では hydrateRoot(dom, <App />) するための <App> をどこから持ってくるか?
Next.jsが出てこないReact Server Componentsハンズオン の クライアントサイドの実装 では、RSC のプロトコルを HTML に埋め込み、それを利用して <App> を組み立てていた。
なるほどーと思いつつ、一応 Next.js 13 を利用して RSC を使う場合と使わない場合に生成される HTML や処理を比較してみた。
Next.js における Hydration の比較
Next.js 13 app(beta) の Hydration
Next.js 13 app(beta) では、デフォルトで全てのコンポーネントが SC として扱われ Vercel 等にサーバーとしてホスティングすることで従来どおり SSR を行ってくれる。
コードは以下で、yarn create next-app --experimental-app したものをそのまま利用。
https://github.com/pokuwagata/rsc-ssr-example
Vercel にデプロイした。
https://rsc-ssr-example.vercel.app/
<script> self.__next_f.push([ 1, 'J1:["$","@2",null,{"assetPrefix":"","initialCanonicalUrl":"/","initialTree":["",{"children":["",{}]},null,null,true],"initialHead":[["$","title",null,{"children":"Create Next App"}],["$","meta",null,{"content":"width=device-width, initial-scale=1","name":"viewport"}],["$","meta",null,{"name":"description","content":"Generated by create next app"}],["$","link",null,{"rel":"icon","href":"/favicon.ico"}]],"globalErrorComponent":"$3","children":[null,null,[["$","link","0",{"rel":"stylesheet","href":"/_next/static/css/876d048b5dab7c28.css","precedence":"high"}]],["$","html",null,{"lang":"en","children":[["$","head",null,{}],["$","body",null,{"children":["$","@4",null,{"parallelRouterKey":"children","segmentPath":["children"],"hasLoading":false,"template":["$","@5",null,{}],"notFound":["$","div",null,{"style":{"fontFamily":"-apple-system, ...
HTML を確認すると、このような RSC プロトコルが埋め込まれていて、ここから React コンポーネントツリーを生成して hydrateRoot に渡す模様。
Chrome の Performance タブから Eventlog を見ると以下のように Hydration が実行されている。

通常の Next.js 13 の Hydration
コードは以下で、yarn create next-app しただけ。
https://github.com/pokuwagata/no-rsc-ssr
Vercel にデプロイした。
https://no-rsc-ssr.vercel.app/
<script id="__NEXT_DATA__" type="application/json">{"props":{"pageProps":{}},"page":"/","query":{},"buildId":"lJbXQiPUmF0U5zQNgNPB2","nextExport":true,"autoExport":true,"isFallback":false,"scriptLoader":[]}</script>
HTML を確認すると、このように通常の Hydration 用のデータが埋め込まれているだけなので、Hydration には HTML 文字列をそのまま利用すると思われる(RSC 以前の 典型的 Hydration)
Chrome の Performance タブから Eventlog を見ると以下のように Hydration が実行されている。

RSC の場合に比べると、Hydration 時間が長い。React が解釈しやすいように予め生成されているプロトコルを利用する方が Hydration しやすいということなのかもしれない。
パフォーマンス
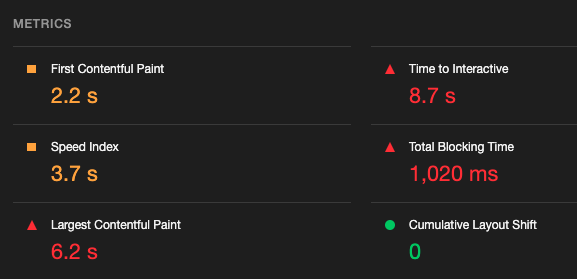
Lighthouse で測定して比較してみると、若干 RSC を使っている方が TTI や TBT が小さく出る傾向がありそうだった。
RSC を使った場合
RSC を使わない場合

まとめ
フロントエンドの各種パフォーマンス指標の定義を図で整理する
フロントエンドのパフォーマンス指標は種類が多くて各指標の定義や関係性を把握するのが難しいと感じる。自分はよく分からなくなるので整理するために図にしてみた。
各指標の定義と関係性

図を作るにあたり以下の URL の内容を参考にした。TTFB と SpeedIndex は図に含めていないので詳細は該当リンクを参照。
| 指標 | リンク |
|---|---|
| LCP | https://web.dev/lcp/ |
| FID | https://web.dev/fid/ |
| CLS | https://web.dev/cls/ |
| TTFB | https://web.dev/ttfb/ |
| FCP | https://web.dev/fcp/ |
| TBT | https://web.dev/tbt/ |
| TTI | https://web.dev/tti/ |
| SpeedIndex | https://developer.mozilla.org/ja/docs/Glossary/Speed_index |
Core Web Vitals vs Lighthouse
パフォーマンス指標のついでに補足。Core Web Vitals と Lighthouse は何が違うのか? そもそも Core Web Vitals とは何なのか?
- Core Web Vitals はパフォーマンス指標のサブセット(グループ)
- Lighthouse や PageSpeed Insights などのツールで測定できる
- Web Vitals より引用
Core Web Vitals に含まれている各指標は、ユーザー エクスペリエンスに関する特徴的な観点を提供し、フィールド データの測定が可能であり、ユーザーを中心とした重要な結果に基づく実際のユーザー体験を反映します。
- Lighthouse はパフォーマンス指標の測定やベストプラクティスの提案を行う解析ツール
指標別に表にするとこうなる。
| 指標 | Core Web Vitals に含まれる | Lighthouse で測定できる |
|---|---|---|
| LCP | ○ | ○ |
| FID | ○ | ☓(TBT で代用) |
| CLS | ○ | ○ |
| TTFB | ☓ | ☓ |
| FCP | ☓ | ○ |
| TBT | ☓ | ○ |
| TTI | ☓ | ○ |
| SpeedIndex | ☓ | ○ |
Lighthouse は Core Web Vitals を測定できることになっているが、FID は測定できない。代わりに TBT を測定するらしい。TBT と FID は多くのケースで近似できるということなんだろうか? (Core Web Vitals を測定するためのツール を参照)
2022 年を振り返る
仕事
今年は*1 React Native (Expo) を利用したネイティブアプリ開発のプロジェクトで、主に Expo を利用した基盤整備を担当していた。具体的には
- GitHub Actions で EAS Build / Update をフックする処理を書いたり
- AWS Lambda でビルドされたアプリを S3 に転送する非同期処理を書いたり
- アプリがプッシュ通知を受信できるようにしたり
- Config Plugin と呼ばれる機構の上で TypeScript を使って Swift / Java をメタプログラミングをしたり
自分は Web のフロントエンドエンジニアなのだが、React Native で画面を作ること 以外 の様々なことをやっていた。
そもそも自分はネイティブアプリの開発経験はなく、当然 Expo なんて聞いたこともないような状態からのスタートで、技術的にはかなりチャレンジングでハードだった。それに加えてプロジェクト固有の技術的な制約というか高難度の課題が多数あり、まあ何というか一言で言うとやばかった。
また、基盤整備と並行してチーム向けの翻訳業みたいなこともやっていた。英語で書かれた公式ドキュメントを読みながら手を動かし、分かったことを社内向けに整理して書いた。開発環境の構築手順だとかローカル環境で実機端末を利用する方法だとか、そもそもの Expo に関する概念の説明とかなんかとにかく色々書いていた気がする。自分は英語のリーディングには慣れているとはいえ、毎日のように長時間英文を読んで試行錯誤するのはそれなりに負荷の高い活動だった。
あとは Four Keys に触発されてチームの生産性を定量化するシステムを突貫で整備したりとかもしてた。取り組みの詳細は会社のテックブログにも投稿した(GitHub Actions で開発リードタイムとデプロイ数を計測してダッシュボードを作っている話)
技術面以外でも、一緒に働くのが初めてのチームメンバーがほとんどだったり、社外の人も多く入っていたりで新しいことが多く大変だった。
色々な面で分からないことだらけの中、とにかく神経を集中させ自分が積み上げてきた能力と経験を全力でぶつけ続けるような毎日だった。なんとかある程度の成果を出すこともできたと思うし、その過程で更に成長することもできたんじゃないかと思っている。
ただ、良い面ばかりではなくて、今から振り返るとこれは自分にとってそれなりの痛みを伴う身を削るような挑戦でもあった。この経験から今後長くエンジニアとしてのキャリアを続けるために必要な様々なことを身をもって知ることができたと思う。具体的には
- 生活習慣(健康管理)
- 仕事と私生活の切り替え(あるいは仕事との距離感)
- 仕事の選び方
等を見直す必要があることを痛感した。
これまでの自分は心身の健康についてあまりにも恐れを知らなすぎたのかなと思うし、今思うとその無鉄砲さ(あるいは全能感)と純粋さが”若さ”というものの一面なのか、とも思ったりした。この業界で自分よりも長くキャリアを積んでいる(生き残っている)シニア勢の凄さは必ずしも技術力だけではなく、むしろ長期間に渡り仕事を継続できている持続性にこそあるのだという風にも考えるようになった。これはエンジニアに限らずどんな職業でもそうなのかもしれない。
今年の仕事について総括すると、色々と複雑な思いはありつつも、育児が始まる前という仕事にかなりのリソースを割り当て可能な最後の時期に、自分の限界に挑戦するような(したいと思えるような)機会を得ることができて(そして20代という人生の中では比較的早い段階で、適度に怪我をして学ぶことができて)良かったんだと前向きに捉えている。勝つことばかり知りて負くるを知らざれば、害その身に至る。
育児
8 月に息子が誕生した。これに伴い 9 月から育児休業休暇を取得していて 2023 年 4 月に復帰予定。
育児の方はそれなりに不安があったが、何とか基本的なお世話スキルを習得して対応できていると思う。
自分はこれまでの人生で赤ちゃんを抱いたこともほとんどなく、自分よりは妻の方がスキルが上だったので、モブプロの知見を活かした "モブお世話" をすることで知識の獲得やお世話内容の認識を揃えた。今はオムツ替え・寝かしつけ・ミルク・入浴・着替え・保湿等ほぼ全ての育児タスクを自立して行うことができるようになっている。
あとはエンジニアの育児っぽい話で言うと、育児記録アプリ「ぴよログ」を利用して息子の行動ログを取っているのも良い取り組みと感じている。記録の対象は例えば、入眠時刻、排泄、ミルクの飲量(と時刻)などそういうもの。蓄積したデータの分析まではしていないが、単純に息子の健康状態のモニタリングや夫婦間での共有として役に立っている(今日は食欲がないとか、💩してないとか)
最近の自分の生活はこんな感じ
8:30 起床・散歩 9:00 朝飯 9:30 コーヒー、日経新聞を読む、株式市場の動向チェック 11:00 読書 12:00 昼飯 13:00 NHK の列島ニュースを視聴。特に意味はないが、全国のローカルニュースを見て和む。 16:00 息子散歩、買い物、妻に育児を任せられる場合は自分の時間(技術の勉強、読書、ジム、昼寝等) 18:30 夕飯 19:30 風呂 20:30 株式市場の振り返り・個別銘柄の研究やポートフォリオ見直し 21:00 息子寝かしつけ、ギター練習 22:30 就寝
新生児や乳幼児は昼夜の区別がないらしいが、今は夜 22時~6時頃までは連続して寝てくれるようになり大人の側の生活も安定してきた。
スケジュールだけ見るとわりと優雅な生活を送っているように見えるが、常時割り込みで発生するお世話タスクを処理しながらなので見た目よりはずっと忙しい。1回の授乳や寝かしつけは 30分以上はかかるし、常に割り込みの可能性があるので、ポモドーロテクニックで言う 1ポモ(25分) 完全に集中する時間を取るのも工夫しないと難しい。なので、集中したいときは「これから作業する」と妻に宣言して育児は全て任せて、自分にも声をかけないようにしてもらっている。逆に普段は割り込みが入る前提で、読書とか録画の視聴とかそこまで中断がストレスにならないことをするようにしている。
あと、子供は可愛いです。
技術
時間を見つけて自分が興味のあるテーマを掘り下げて学習している。例えば
- Next.js 13 の /app の検証として、新しいキャッシュや ServerComponent の取り扱い方を試したり
- デザインシステムの概念について知るために「Design Systems ―デジタルプロダクトのためのデザインシステム実践ガイド」を読んだり
- HTML の学習のために「HTML解体新書」を読んだり
- Chakra UI のコードを読んで基本的なコンポーネントのお手本実装を学んだり
今年の業務ではほとんど Web のフロントエンドを担当していなかった反動もあり、それなりに楽しくやれていると思う。
株式投資
2021 年にポジションを取ってからは塩漬け状態で特に何もしてなかったのだが、育児中に並行してできることがスマホで読書をすることぐらいしかなくて、色々な投資本に目を通していった結果また個別株投資をやりたくなってきたので再開した。
まずは去年から -30% 近くの損失になっていた銘柄を全て損切りすることから始めた。よく、株の初心者は損切りできないから致命傷を負うという話を聞くことが多いが、まさに自分がそうで、「そのうち戻すんじゃないか」とか「損切りしなければ損失ではないんだ」みたいな考えに陥って塩漬けにしていた。こういう冷静に考えると当たり前のことが、いざ自分の身銭で相場を張るとなかなかできないものなんだと痛感させられる。
勇気を出して損切りを終え、これまでのファンダメンタル偏重のやり方を止めて色々な手法を試してみることにした。『ズボラ株投資 月10万円を稼ぐ「週1ラクすぎトレード」』という本を読み、テクニカル指標で大型株のトレードをやってみたり、『1勝4敗でもしっかり儲ける新高値ブレイク投資術』や『忙しい人でも1日10分から始められる 3年で3人の「シン億り人」を誕生させたガチ投資術』を読んで、小型成長株のモメンタム投資をやってみたりした。11・12 月はこのモメンタム投資の手法中心でプラスのリターンを得られている。
個別株投資を再開してから、以前に停止していた日経新聞の購読を再開した。前よりも政治や経済のニュースを株価の動きと関連付けて読むようになったので記事の理解度が上がり、興味を持てる記事も増えた気がする。個別株投資はリターンのお金よりも経済だったり企業の財務指標だったりを理解するのに有効な取り組みだと感じる(もちろんちゃんと自分で考えて投資をしない人にとってはただのギャンブルでしかない)
個別株投資をする一方で、2022 年はつみたて NISA で S&P500 の投資信託を毎月約 3 万円分購入し上限の40万円分を使い切ることができた。今年は S&P 500 が年初来 -20 % と大きく下げているので積立を始めるには去年・一昨年よりはむしろ良い環境だった。市場の景気後退懸念は依然として根強いので、あと数年は仕込み時と言えそう。
来年のつみたて NISA は S&P500 に加え新興国の指数連動型へも 20% 程度資金を分散させるつもりでいる。
世界の企業時価総額ランキングの30年間の変遷を見ると、80年代後半(日本のバブル期)には日本企業が多く入るなど、年代によって企業の入れ替わりはそれなりにありつつも米国企業だけが一貫して多く上位に残り続けていることから米国はやはり投資先として外せない一方で、最近は中国などの新興国のテック企業がちらほら上位に入るようにもなってきているという傾向や、人口動態の予測の面から新興国(特に中国・インド)に長期投資するのも合理的なのではないかと考えて 20% 程度資金を振り分けようと思った。
そういう意味でオルカンもありかと思ったが、米国以外の先進国が 30% ぐらい入っていて新興国の割合が少ないので選択肢からは除外した。先進国といっても例えば日本から今後10-30 年間の間にグローバルで競争優位性を持つ大企業が誕生するか?と言われるとあんまりイメージがつかない。やっぱり米国は特別だと思う。
今後、つみたてNISA の年間投資上限額が 40 万円から 360 万円まで引き上げられる方向で調整されているという報道もあり、そうなると経済的自由の達成にはますます入金力の重要性が上がるので、自分の年収を上げていかないとなーとぼんやり思いながら毎月転職ドラフトには参加している。
読書
技術系、投資本以外だと、
等を読んで政治・経済の勉強をしていた。後は司馬遼太郎の「街道をゆく」シリーズとか「竜馬がゆく」なんかも3巻ぐらいまで読んでいた。とにかく育児と同時にできることが読書だけなので、興味に任せて色々読んでいた。
ギター
今年も本当にちょっとずつだが練習していた。GT-1 というマルチエフェクター兼オーディオインターフェイスを購入し、PC 上で LINE 録音できるようにして自分の演奏の下手さに絶望したり、思ったよりはできてるじゃんと思ったりしていた。God Knows... のイントロは未だに弾けません(特にプリングの速度不足)
2023 年
まずは自宅近くの保育園に受かってくれマジで頼む。今年は出生数も少ないし 0 歳入園だし 1 番入園確率高いはずなんだがどうなることやら。
仕事の方はこれだけ長期間の休業は初めてなので無事に社会復帰できるかどうかも心配だが、家庭とバランス取りながら無理ない感じでやっていきたい。
まあそんな感じで 2023 年よろしくお願いします。
*1:といっても育児休暇に入る9月までだが
書籍「Clean Agile」を読んで、アジャイル開発の正しさを支えるソフトウェア開発の経験則について考えた
書籍「Clean Agile 基本に立ち戻れ 」を読んだ。
この書籍は、アジャイルソフトウェアマニフェストを策定したスノーバードの会議の主催者でもある Robert C.Martin 氏 が、近年広まっているアジャイルに関する誤解を解くために、アジャイルの歴史やアジャイルとは何なのかについて改めて説明しようという趣旨で書かれている。
書籍全体を通じて、「アジャイル開発の正しさはソフトウェア開発に関するいくつかの経験則が正しいということを前提にしている」ような記述が多かったことが個人的に面白かった。著者のロジックとしては、これらの経験則が真であるからこそウォータフォール開発は失敗しアジャイル開発が妥当な開発プロセスなのだ、ということのようだった。
これらの経験則は書籍の中で1つのリストとしてまとめられているわけではなく、文章の流れの中で必要に応じて言及する形になっているので、抜粋して一覧にしてみると便利そうだなと思いリストにしてみた。
アジャイル開発を導入する際には、いきなりプラクティスの説明から入るのではなく、始めにこれらの素朴な経験則についてビジネス側・エンジニア側双方で意見を交わしておくことでアジャイル開発に対する納得度が高まる気がする。
以下が書籍に登場していた経験則の一覧(もしかしたら他にもあるかもしれない)
- 経験則① エンジニアは開発に要する作業時間を正確に見積もることができない
- 経験則②ソフトウェア開発プロジェクトの時間見積もりは不確実性が高い
- 経験則③遅れているプロジェクトへの要員追加は更にプロジェクトを遅くさせる(ブルックスの法則)
- 経験則④品質を下げても(汚いコードを書いたりテストを省略しても)プロジェクトは加速しない
- 経験則⑤品質、速度、費用、要件の全てを満たすことはできない
- まとめ
経験則① エンジニアは開発に要する作業時間を正確に見積もることができない
はい。ここまできっぱり断言されると気持ち良い感じがする。
実際にコードを書き始めてみると、当初の見積もりとは全然違う工数になりそうだと分かるという経験はエンジニアならあるあるだと思う。そういう場合に大体の人は見積もりが間違っていたかな、次はこうしよう等と反省する。そして運が悪いとマネージャーに「なぜ見積もりを間違えたのか」あるいは「バッファを積みすぎたのではないか」などと質問されて「すいません」みたいなことになったりする。
しかし、ソフトウェアの複雑さを事前に評価することはできないので、この経験則では正確な作業時間見積もりはそもそも不可能だという。これはエンジニアの能力や態度の問題ではなく、ソフトウェアの性質という本質的な問題なのでどうしようもない。
そもそも不可能なことを上手くやろうとしても仕方がないので、アジャイルでは事前の見積もりの精緻化ではなくイテレーションの実績を元にしてスケジュールの問題に対処する。
具体的にはユーザーストーリーという最小限の機能単位と、相対見積もりによる曖昧な数値(ストーリーポイント)を使用して、実績ベースでプロジェクトの残作業(開発対象)やチームの速度を定量化する。
このユーザーストーリーを利用する背景についての明確な説明も自分はこの書籍で初めて知って、ああユーザーストーリーは本来そういうことがしたかったんだなーと腹落ちした感が凄くあった。
経験則②ソフトウェア開発プロジェクトの時間見積もりは不確実性が高い
これは経験則①が真だと仮定するなら当然で、個別の開発タスクを正確に見積もれないのだから、その総和としてのプロジェクトの時間見積もりも正確にはできない。正確にできないどころか大幅に上下する可能性が高い。
また、(特にウォーターフォール開発では)プロジェクトの終盤で要件が変更になったり、想定以上の不具合が検出されるなど、とにかくプロジェクト中は最後まで何が起こるか分からないというのはエンジニアなら感覚として分かることではある。
ウォーターフォール開発で定番のガントチャートは横軸に時間を取るが、そもそもプロジェクトの時間見積もりは不確実性が高いので当然スケジュール通りにはいかないよね、そんなことするよりならユーザーストーリが残り何ポイント分残っているかを視覚化する長期のバーンダウンチャートを使って... みたいな話になっていく。それだけでなく、アジャイルでは各イテレーションで常にリリース可能な状態を保つので、ウォーターフォールのようにプロジェクト終盤のリスクもほとんどない、むしろ時間が経過するほどに実績を元にした見積もりが正確になっていくのでアジャイルは良いよねという話にもなる。
経験則③遅れているプロジェクトへの要員追加は更にプロジェクトを遅くさせる(ブルックスの法則)
Frederick Phillips Brooks 氏が書籍「人月の神話」で提唱した法則。遅延プロジェクトに要員を追加すると更に遅延する。理由として人月の神話では以下のように説明している。
- 追加された要員のオンボーディングに時間がかかるので既存メンバーの時間が奪われ追加前より遅延する
- 開発対象が分割不可能なら(順次的制約が強いなら)そもそも要員を追加しても意味がない(妊婦さんを集めても出産は十月十日かかるしかないという有名な例が人月の神話にある)
- 仮に開発対象が分割できるなら追加要員のために作業を分割するという作業が追加で必要になる
- 分割された作業間でコミュニケーションが必要な場合は(大抵のソフトウェア開発が該当する)以前よりも更にコミュニケーションに時間が取られて進捗が遅くなる
ブルックスの法則については既に研究論文で実証もされている、らしい*1。研究の結果として法則は大きくは間違っていなさそうという結果が得られているし、ソフトウェア開発の業界でも多くの人が正しいと認識していることなので、これはもう経験則というより事実と言ってもいいのかもしれない。(ちなみに研究によるとプロジェクト初期の要員追加に限っては有効らしい。まあ初期ならそんなに遅延もしてないし当然なような気もするが)
経験則④品質を下げても(汚いコードを書いたりテストを省略しても)プロジェクトは加速しない
コードレビューやテストコードを省略して開発時間を短縮するというのは個人的によく見聞きする話ではあるが、本書ではこれも明確に間違っていると断言している。
理由としては
- 汚いコードが積み上がると不具合が多くなって修正も困難になるし、機能追加も難しくなる(それはそう。わかりみが深い)
- チームの新規参画者が既存コードを理解しにくい上に、新しく書かれるコードの水準がその汚い既存コードに合わせられるから
むしろ品質を上げることが速度に繋がると強調されていた。一見分かりにくいけどそうなんだよなあ。
この話は有名なスライド「質とスピード」でも取り上げられている。
更にスライド中で、「そもそも上手くコードが書けない人はどれだけ時間を与えても結局は同じようなコードしか書けない」という経験則を述べるツイートが引用されている。これが正しいとするなら、品質を上げるためにはハイスキルなエンジニアを採用するか育成するしかないことになる。だからジュニアのエンジニアはチームに不要なんだとまでは言わないが、ペアプログラミングやレビューをして品質を期待する水準まで高める必要がある(余談だがこういうところでも、「人月」という人と月が交換可能であるかのような概念でエンジニアを扱うことがいかに愚かなことかというのが分かる)
優秀なエンジニアがもたらす品質が速度となってプロダクトの競争力の源泉となり、最終的にはビジネス上の優位性となるのであれば、各社エンジニア採用にコストをかけて様々な工夫をしているのも頷けるなあという感じがする。
経験則⑤品質、速度、費用、要件の全てを満たすことはできない
言い換えると、「可能な限り費用を抑えながら、最高の品質で最高の機能を持つ製品を最高の速度で提供することはできない」これはまあそう、という感じで異論ないと思う。
インセプションデッキのワークショップに登場するトレードオフスライダーと同じで、どれかを高めるためにはどれかを低くする必要がある。
ただし本書では、これまでに挙げてきた経験則を踏まえると論理的に考えてアジャイルではスケジュールを守るためには要件(スコープ)以外は変えられない。変えても意味がないという主張がなされる。
これはどういうことかを簡単に書くと
- まず経験則④から品質を下げても速度が下がるので品質を落とすという選択肢はなくなる
- 次にブルックスの法則から、速度を上げるために要員を追加してもむしろ遅延するので費用を上げる選択肢もなくなる
- すると残っているのは要件(スコープ)しかない。スケジュールを守るためにはスコープを変更するしかない。
とても論理的で筋が通った説明に感じる。ビジネス側に、あるいはマネージャーに対して、アジャイル開発をする以上はスコープを変更するかスケジュールを変えるかのどちらかを選択するしかないことを最初に分かってもらうの大事。
まとめ
Clean Agile は今まで読んだアジャイル系の本の中で1番分かりやすくて面白かった気がする。論理的に考えてアジャイルしかない、という点に凄い説得力と魅力を感じた。日本の開発現場では今でもウォーターフォール開発が蔓延している。自分が引退する頃にも日本では多くの人々がウォーターフォール開発をしているんだろうか?
少なくとも自分は本質を捉えた正しいアジャイル開発のチームで仕事したいよなーと改めて思いました。
*1:自分は読んではないが Software Project Dynamics: An Integrated Approachに詳細が載っていると人月の神話に書いていた
Expo の Config Plugin とは何か
ざっくり要約
Expo は JavaScript (React Native) で iOS / Android / Web で動作するアプリケーションを開発できるフレームワーク。また、Expo で開発したアプリケーションをビルド・配布・アップデート可能な SaaS でもある。
フレームワークとしての Expo は、完全に JavaScript のみで開発が完結する Managed Workflow と、iOS / Android アプリの実装言語(Swift, Kotlin, etc)を使ってネイティブ領域の実装を変更可能にする Bare Workflow の 2つのモードがある。
一般的に、Firebase 等の外部サービスを利用するために SDK を組み込む際には、起動時処理の変更のためネイティブ領域のコードを変更する必要がある場合があるが Managed Workflow ではそれができなかった。
Config Plugin を使うことで Managed Workflow のまま JavaScript を使ってネイティブ領域のコードをメタプログラミング可能になるので Bare Workflow にする必要がなくなり、Web のフロントエンドエンジニアにとってはよりネイティブアプリの開発の敷居が下がる。
というのがざっくりとした Config Plugin に対する自分の理解だが、以下で更に掘り下げていきたい。
Conifig Plugin とは
公式ドキュメントから引用すると
Config plugins are a system for extending the Expo config and customizing the prebuild phase of managed builds.
https://docs.expo.dev/guides/config-plugins/
(訳)Config Plugin は Expo Config を拡張し、managed ビルドの prebuild フェーズをカスタマイズする仕組みです。
managed ビルドというのは Managed Workflow を利用したビルドのことだが、prebuild フェーズをカスタマイズするとはどういう意味なのか?
prebuild フェーズって何?
公式ドキュメントから引用すると
In Expo, prebuilding is the process of generating the native runtime code for your React project. Prebuild can be used to automatically link and configure complex native modules that have implemented CocoaPods, autolinking, and config plugins.
https://github.com/expo/fyi/blob/main/prebuilding.md
(訳)prebuild とは、ネイティブランタイムコードを生成するプロセスのことです。PreBuild は Native Modules を自動的に結合、設定するために利用されます。
prebuild フェーズにおいて、Managed Workflow の場合は、/ios と /android ディレクトリを生成し、Config Plugin として実装されたコードを元にディレクトリ内のネイティブランタイムコードを書き換える。
これは、仮に Config Plugin がなかったとしても、Managed Workflow のプロジェクトをアプリとしてビルドする場合には必ず通過するフェーズ。
最終的には Managed Workflow で開発していても普遍的なネイティブアプリとしてのコードベースに変換する必要がある(当然といえば当然)
Config Plugin は SDK 毎に開発
多くの場合、Config Plugin は外部の SDK(Native Modules) 毎に作成する。その SDK に必要なカスタマイズを SDK 毎に作成した Config Plugin に記述する。
なので、起動時処理などは SDK 間で同じファイルの同じ箇所を変更する競合が発生する可能性があるので注意をする必要がある。
Config Plugin が必要かどうかの判定方法
外部の SDK を利用したい場合に、Config Plugin が必要なのかどうかはどうやって判断すればいいのか?
ちなみに純粋な iOS / Android アプリ向けの SDK しか存在しない場合は React Native 向けの SDK を開発する必要があるので、Config Plugin 以前に最初はそこから始めるということになる。
既に公開されている Config Plugin がないかを探す
有名なサービスであれば既に公開されている場合もあるので、もし公開されているなら必要だと分かるし単純にそれを使えば OK
もし上記のリポジトリにもなく、サービスから公式に提供されているものがないのであれば、自分で必要性の有無を判断する必要がある。
SDK のドキュメントがある場合
ドキュメントを読み、ネイティブコードを書き換える必要があるかどうかを確認する。
例えば Repro なら SDK 導入手順がドキュメント化されていて、AppDelegate.m の書き換えが必要なことがわかる。
https://docs.repro.io/ja/dev/sdk/getstarted/react-native.html#id5
これは、Managed Workflow の場合は直接編集不可能なので Config Plugin を開発し、以下のような書き換え処理を TypeScript (JavaScript)で実装する。
const addImport = (contents: string): string => { if (contents.includes("@import <Repro/Repro.h>;")) { return contents; } else { return contents.replace( /#import "AppDelegate.h"/g, `#import "AppDelegate.h" #import <Repro/Repro.h> `, ); } };
SDK のドキュメントがない場合
とりあえず Config Plugin なしでビルドが通るか、きちんと動作するかを試してみるしかない。
Config Plugin を開発したい
自分が使いたい SDK に対して、どうやら公開されている Config Plugin もなさそうだしドキュメントを読むとネイティブコードを書き換えないといけないらしいという場合は自分で開発するしかない。ではどうやって開発するのか?
これは既存の実装を真似るしかない。。
自分は上記の Config Plugin を集めたリポジトリを参考にして何となく開発できたので、あまり尻込みせずに挑戦してみても良いと思う。
git のブランチ命名とコミットメッセージのルール
所属企業で代々引き継がれている(と思う) git のブランチ命名とコミットメッセージのルールを汎用化してみた。
ブランチ
形式:<type>-<scope>/<task-number>-<name>
具体例
scope を使用する場合
feat-ui/ABC-123-add-nice-feature
scope を使用しない場合
fix/ABC-123-fix-bad-bugrefactor/ABC-123-remove-chaos
type
| type | 説明 |
|---|---|
| feat | 新しい機能追加 |
| fix | バグの修正等 |
| refactor | リファクタリング |
scope
モノレポやチームによっては何か定義してもいいかも。不要な場合もある。
task-number
JIRA だと ABC-123 とか。チケットの運用方法(チケットがどこからも参照されない、本文の情報量が少ない等)によっては不要な場合もある。
name
何をするブランチなのかが分かる文言を書く。add-nice-feature とか。
コミットメッセージ
形式:<type>(<scope>): <task-number> message
具体例
scope を使用する場合
feat(ui): ABC-123 X の機能を実装
scope を使用しない場合
docs: ABC-123 README の記述が古くなっていたので変更
type
| type | 説明 |
|---|---|
| feat | 新しい機能追加 |
| fix | バグの修正等 |
| refactor | リファクタリング |
| docs | ドキュメント |
| package | npm パッケージ関連 |
| test | テストコード関連 |
バグ修正と同時にリファクタにもなってるとか、機能実装と同時にテストコードを書いている場合はどうするんだとか色々例外ケースはありそうだが、まあ雑にどれかを選んでおけば十分じゃないかなと思う。
scope, task-numer
ブランチと同様
message
何をしたコミットなのかが分かる文言を書く。多分(日本語話者のチームでは)日本語で書く人が多い。
そんなにコミットメッセージって大事?
自分は大事な場合”も”あると考えている。自分の経験でいうと実際に、リリースから 5~10 年ぐらい経過しているプロダクトの運用保守をしたときには blame で行単位のコミットメッセージを読むと調査の役に立つことが多かった。
if 文の分岐 1行だけでも、長期間運用されていると様々な理由で変更される。最初のリリースからの不具合の修正、仕様変更、別の機能追加に伴う改修など...
なぜそのコミットが行われているのか、関連するチケットや PR は何なのか、改修した際にどういう検証をしたのか等が分かるのは本当に助かった。
どちらかというとコミットメッセージ自体というかチケットや PR に情報が集約されている前提で、そこにコミットメッセージからアクセスできると、(長期間の運用保守が想定されるプロダクトなら)嬉しいね、ということかもしれない。
なので、 1 年続くか不明なプロダクトならコミットメッセージやチケット上の情報整理にあまり時間を費やさない方が賢い選択かもとは思う。